项目简介
这个项目是用来记录任务我在阅读《Linux是怎么工作的》过程中所写的程序以及相关的感悟。
正文
01 用户模式实现的功能
本章是这本书中的第二章,主要内容就是从用户的应用程序入手介绍双模式下,Linux是怎么进行模式转化的。
例程: hello world
1 |
|
距离我第一次在计算机上敲下这段代码已经是7年前的事情了,我并没有像硅谷的电脑天才们那样对着黑色的控制台产生多大的兴趣,反倒觉得这很无聊。(跑题了
可以使用strace对进程进行跟踪,查看进程中的代码是怎么样在更深层处理的。(Fedora 48需要安装strace)
1 | strace -o hello.log ./hello |
对于Linux中的系统调用的函数虽然不能直接在程序中调用,但是可以通过 man 命令进行查看。
上面这段的大致流程就是执行 - 申请一块内存区域 - 调用write - 结束。
例程: loop & ppidloop
1 |
|
使用 sar 命令(需要安装 sysstat ),可以间隔的采集 CPU 核心的使用情况。
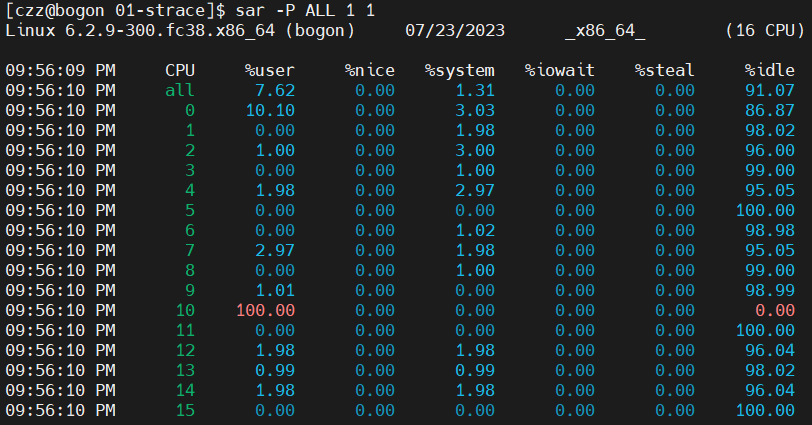
在 %user 字段10核100%的运行时间,书中给的例子是始终占着 0 核,而我在多次调用命令后,会出现不同 CPU上跑的情况。(可能有啥稀奇古怪的调度算法?
而在将程序更改成获取父进程的进程 ID 后。
1 |
|
%user 字段与 &system 字段呈现了一下的比例关系。
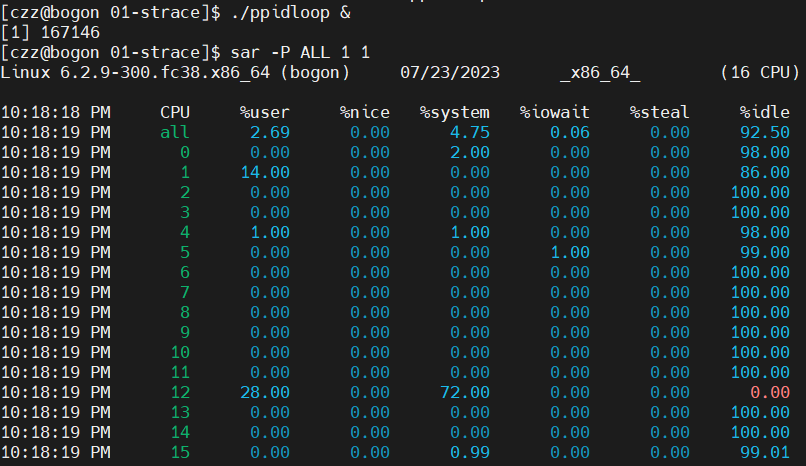
● 在 CPU 核心 12 上,运行 ppidloop 程序占用了 28% 的运行时间
● 根据 ppidloop 程序发出的请求来获取父进程的进程 ID 这一内核处理占用了 72% 的运行时间
用户模式:内核模式 = 28:72
为什么 %system 的值不是 100% 呢?这是因为,用于循环执行 main() 函数内的 getppid() 的循环处理,是属于进程自身的处理。
ldd 命令可以查看程序所依赖的库
小结
在我看来,系统调用在 Linux 中对于开发人员起到了包装作用,对系统调用的实现进行封装,使开发人员更专注于上层的应用开发,剩下的底层工作通通丢给 Linux 系统调用。
02 进程管理
例程: fork
1 |
|
fork 在执行时,会将父进程的所使用到的所有内存空间中的数据进行复制,复制以后重新开辟一块新的空间用于子进程,让 cs:eip 指向新进程的指令部分,此时两者便相互独立。
利用父进程中调用 fork 返回子进程 PID,而在在子进程中返回的是 0,执行失败返回 -1 的特性,可以实现不同处理。
在 Linux 中,启动一个进程时需要调用 execve ,而在 Linux 内核运行进程的流程:
- 读取可执行文件,读取创建进程的内存映像所需的信息
- 用新进程的数据覆盖当前进程的内存
- 从最初的命令开始运行的新的进程
首先,可执行文件不仅包含进程在运行过程中所使用的代码与数据,还包含开始运行程序时所需要的数据。
- 包含代码的代码段在文件中的偏移量、大小,以及内存映像的起始地址
- 包含代码以外的变量等数据的数据段在文件中的偏移量、大小,以及内存映像的地址
- 程序执行的第一条指令的内存地址(入口处)
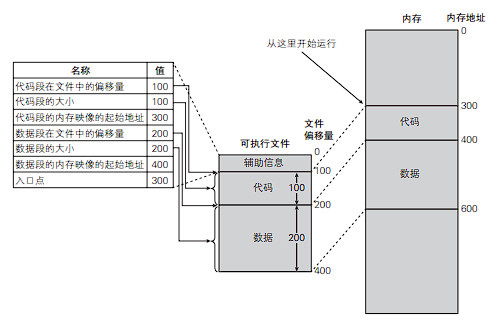
在 Linux 中可以通过 readelf 查看可执行文件与可链接格式文件的 ELF 信息,程序运行时可以从 /proc/(pid)/maps 查看进程的内存映像信息。
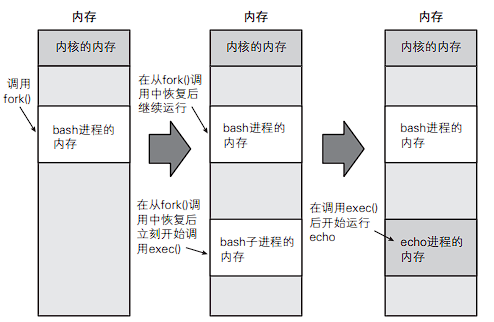
在新建进程时,采用 fork & exec 的方式,由父进程调用 fork 创建子进程,再由子进程调用 exec。
例程: fork-and-exec
1 |
|
在此例程中,通过 fork 出的子进程,在子进程执行 exec 从自身的入口开始执行代码,最终执行 exce 实现 echo "hello" 的操作。
而结束进程可以使用 _exit 函数(底层发起 exit_group 系统调用),而实际编写代码直接使用 C 标准库中的 exit 函数,C 标准库会在调用完自身的终止处理后调用 _exit 函数,对于内存就是将进程所占用的内存重新还给系统。
03 进程调度器
本章主要讲述进程的调度,包括进程状态、逻辑处理器、进程优先级影响。(跳过)
taskset 命令 Linux 提供的调度器相关的程序
04 内存管理
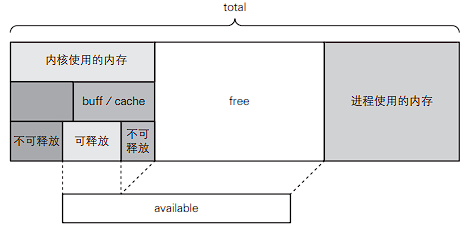
在 Linux 中 free 命令查看内存总量和已消耗的内存量,需要注意的是 available 字段的内存正常情况下大于 free 中,因为前者包括内核可以释放的内存量,指缓冲区缓存与页面缓存中的大部分内存,以及内核中除此以外的用于其他地方的部分内存。
虚拟内存
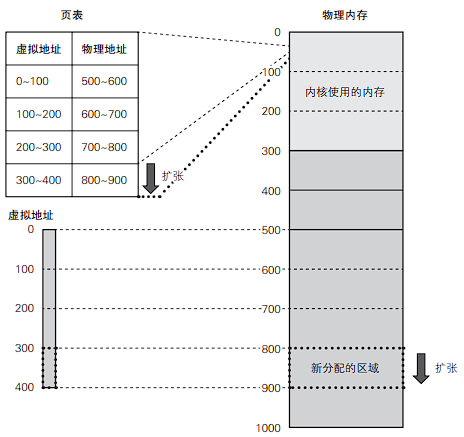
页表完成从虚拟地址到物理地址的转换,在虚拟内存中,所有内存都以页为单位划分并管理。页表中,一个页面对应的数据条目成为页表项,其记录虚拟内存与物理内存的映射关系。
当进程访问页表中不存在的内存地址时,变产生缺页中断,内核的缺页中断机构检测到非法访问,向进程发送 SIGSEGV 信号, 接收到该信号的进程通常会被强制结束运行。
在读取一个程序的可执行文件时,根据前面提到过的辅助信息,在物理内存上划分出一定大小的区域,分别将代码、数据分开存入,复制完成后,创建进程的页表,并把虚拟地址映射到物理地址。
如果进程请求更多内存,内核将为其分配新的内存,创建相应的页表, 然后把与新分配的内存(的物理地址)对应的虚拟地址返回给进程。
例程: mmap
1 |
|
mmap 函数会通过系统调用向 Linux 内核请求新的 内存。另外,system 函数会执行第 1 个参数中指定的命令。本程序利用这个函数输出了申请内存前后的内存映射信息。
例程: filemap 文件映射
文件映射属于虚拟内存的应用的一种,进程在访问文件时,通常会在打开文件后使用 read()、write() 以 及 lseek() 等系统调用。此外,Linux 还提供了将文件区域映射到虚拟地 址空间的功能。 按照指定方式调用 mmap() 函数,即可将文件的内容读取到内存中, 然后把这个内存区域映射到虚拟地址空间。
● 文件是否被映射到虚拟地址空间?
● 能否通过读取映射的区域来读取文件内容?
● 能否通过向映射的区域写入数据来将数据写入文件?
1 |
|
请求分页
在以上的内容中,对于创建进程时的内存分配,或者在创建进程后通过 mmap 系统调用进行的动态内存分配,我们是这样描述它们的流程的。
① 内核直接从物理内存中获取需要的区域。
② 内核设置页表,并关联虚拟地址空间与物理地址空间。
但是,这种分配方式会导致内存的浪费。因为在获取的内存中,有一 部分内存在获取后,甚至直到进程运行结束都不会使用,
在请求分页机制中,对于虚拟地址空间内的各个页面,只有在进程初 次访问页面时,才会为这个页面分配物理内存。页面的状态除了前面提到 过的“未分配给进程”与“已分配给进程且已分配物理内存”这两种以外, 还存在“已分配给进程但尚未分配物理内存”这种状态。
在过往的认知中,一直以为虚拟内存仅仅是做了让各个进程相互隔离互不干扰以及方便物理内存映射分配的作用,然而此外,在一个进程需要访问新的内存空间时,并不会立即立即分配给进程,而是有一个“成功获取虚拟内存” -> “成功获取物理内存”的过程,这便是请求分页。
此时的处理流程如下所示。
① 进程访问入口点。
② CPU 参照页表,筛选出入口点所属的页面中哪些虚拟地址未关联 物理地址。
③ 在 CPU 中引发缺页中断。
④ 内核中的缺页中断机构为步骤①中访问的页面分配物理内存,并更新其页表。
⑤ 回到用户模式,继续运行进程。
在这个过程中,进程并不会感知到自身在运行中曾发生缺页中断。
在这之后,当进程需要访问新的区域时,先出发缺页中断,再分配物理内存,更新页表。调用 mmap 函数动态获取内存同样的流程。进程通过 mmap 函数等成功获取内存”表述为“成功获取虚拟内存”,将“访问所获取的虚拟内存并将虚拟内存关联到物理内存”表 述为“成功获取物理内存”。
例程: demand-paging 请求分页
● 在获取内存后,是否只会增加虚拟内存使用量,而不会增加物理内 存使用量?
● 在访问已获取的内存时,物理内存使用量是否会增加,与此同时是否会发生缺页中断?
1 |
|
分别使用 sar -r 1 与 sar -B 1 采集系统的内存信息,与缺页中断请求,像上面所讲的,在一个进程中。
● 即使已经获取内存区域,在访问这个区域的内存前,系统上的物理内存使用量(kbmemused 字段的值)也几乎不会发生改变
● 在开始访问内存后,内存使用量每秒增加 10 MB 左右
● 在访问结束后,内存使用量不再发生变化
● 在进程结束运行后,内存使用量回到开始运行进程前的状态
● 在已获取内存但尚未进行访问这段时间内,虚拟内存量比获取前增加了约 100 MB,但物理内存量并没有发生变化
● 在开始访问内存后,物理内存量每秒增加 10 MB 左右,但虚拟内量没有发生变化
● 在访问结束后,物理内存量比开始访问前多了约 100 MB
在进程运行时,如果获取内存失败,进程就会异常终止。但内存获取失败同样分为虚拟内存不足与物理内存不足。
当进程把虚拟地址空间的范围内的虚拟内存全部获取完毕后,就会导致虚拟内存不足。并且,其与还剩余多少物理内存无关。
写时复制
在 fork 函数执行时,可以通过虚拟内存机制提高 fork 的执行速度。
在发起 fork 系统调用时并非把父进程的所有内存数据复制给子进程,而是仅仅复制父进程的页表。
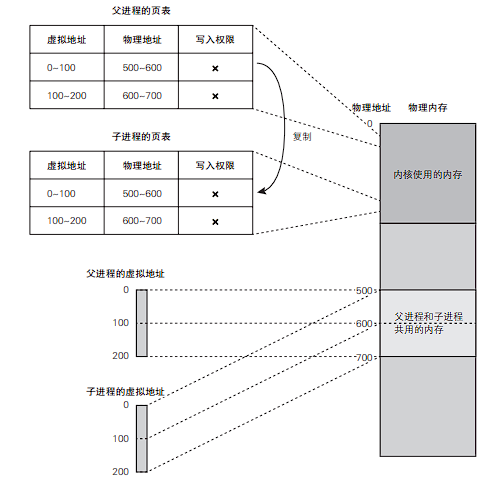
在这之后,假如只进行读取操作,那么父进程和子进程双方都能访问共享的物理页面。但是,当其中一方打算更改任意页面的数据时,则将按照下述流程解除共享。
① 由于没有写入权限,所以在尝试写入时,CPU 将引发缺页中断。
② CPU 转换到内核模式,缺页中断机构开始运行。
③ 对于被访问的页面,缺页中断机构将复制一份放到别的地方,然后将其分配给尝试写入的进程,并根据请求更新其中的内容。
④ 为父进程和子进程双方更新与已解除共享的页面对应的页表项。
● 对于执行写入操作的一方,将其页表项重新连接到新分配的物理 页面,并赋予写入权限
● 对于另一方,也只需对其页表项重新赋予写入权限即可
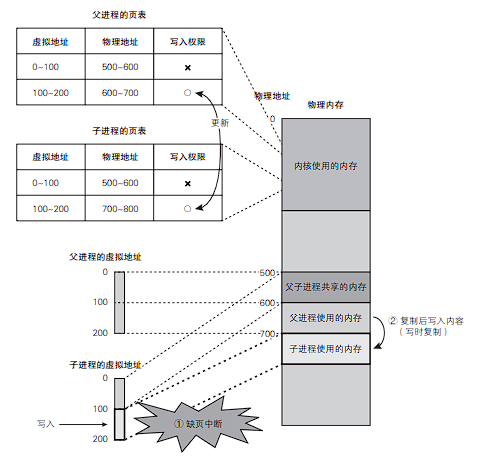
在这之后,对于已解除共享关系的页面,父进程和子进程双方都可以自由地进行读写操作。因为物理内存并非在发起 fork 系统调用时进行复制,而是在尝试写入时才进行复制,所以这个机制被称为写时复制 (Copy on Write,CoW)。
需要注意的是,在写时复制机制下,即便成功调用 fork,如果在写入并引发缺页中断的时间点没有充足的物理页面,也同样会出现物理内存不足的情况。
例程: cow
● 在从调用 fork 到开始写入的这段时间,内存区域是否被父进程和子进程双方共享?
● 在向内存区域执行写入时,是否会引发缺页中断?
1 |
|
● 尽管父进程的内存使用量超过了 100 MB,但从调用 fork 到子进程开始往内存写入数据这段时间,内存使用量仅增加了几百KB
● 在子进程向内存写入数据后,不但发生缺页中断的次数增加了,系统的内存使用量也增加了 100 MB(这代表内存共享已解除)
对于共享的内存,父进程和子进程双方会重复计算。因此,所有进程的物理内存使用量的总值会比实际使用量要多。
以上代码为例,子进程开始写入数据前,父进程和子进程的实际物理内存使用量共为 100 MB 左右,但双方都会认为自己独占了 100 MB 的物理内存。
Swap
在物理系统耗尽时,系统会进入OOM状态。但实际上,Linux 中的 Swap 利用虚拟内存机制,可以将外部存储器的一部分容量暂时当作内存使用。通过这个功能,我们可以将外部存储器的一部分容量暂时当作内存使 用。
具体来说,在系统物理内存不足的情况下,当出现获取物理内存的申请时,物理内存中的一部分页面将被保存到外部存储器(可以是其他进程的内存空间)中,从而空出充足的可用内存。这里用于保存页面的区域称为交换分区 Swap 分区)。交换分区由系统管理员在构建系统时进行设置。
被换出的页面在交换分区上的地址信息记录在内核中专门用于管理交换分区的区域上。
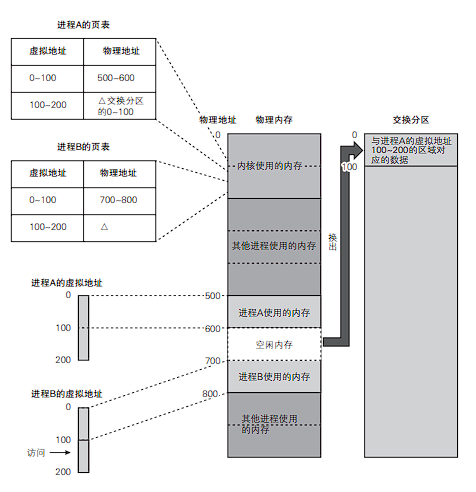
通过换出处理,空出一块可用内存,内核将这部分内存分配给进程B。
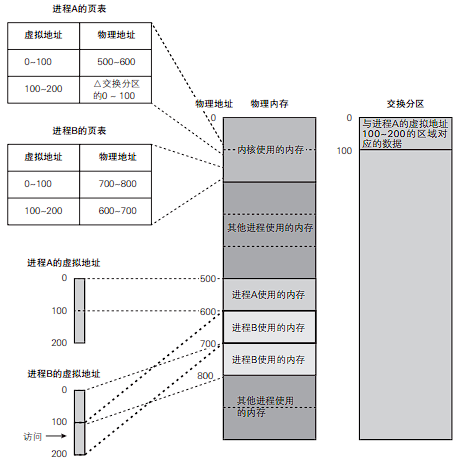
经过一段时间后,系统得以空出部分可用内存。如果进程A对先前保存到交换分区的页面发起访问,内核会从交换分区中将先前换出的页面重新拿回物理内存,这个处理称为换入,如下图。
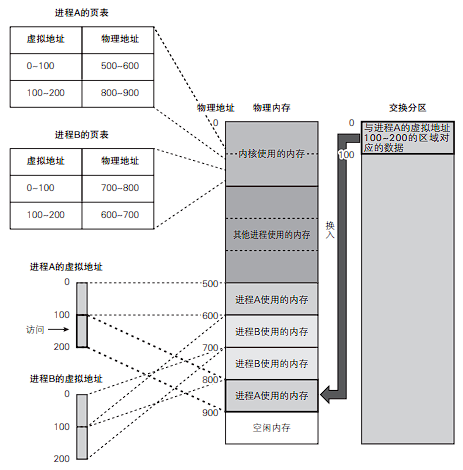
换出与换入这两个处理统称为交换。在 Linux 中,由于交换是以页为单位进行的,所以也称为分页。同时,换入与换出也分别称为页面调入与页面调出。
当系统长期处于内存不足时,访问内存的操作导致页面不断地被换入换出,导致系统陷入系统抖动(颠簸)。
多级页表 & 标准大页 & 透明大页
在 x86_64 架构上,虚拟地址空间大小为 128 TB,页面大小为 4 KB, 页表项的大小为 8 字节。通过上面的信息可以算出,一个进程的页表就需要占用 256 GB 的内存(= 8 B×128 TB / 4 KB)。
因此为了避免使用这样的单层结构导致进程页表占用很大内存,而使用多级页表。
多级页表老生常谈了,建议《黑皮书》。
随着进程的虚拟内存使用量,进程页表使用的物理内存也会增加。
比如 fork 系统调用的速度就会变慢,因为之前提到写时复制创建进程,就导致子进程需要复制一粉与父进程同大小的页表,为解决复制时间上的问题,Linux 提供了标准大页机制。
顾名思义,标准大页是比普通的页面更大的页。利用这种页面,能有效减少进程页表所需的内存量。
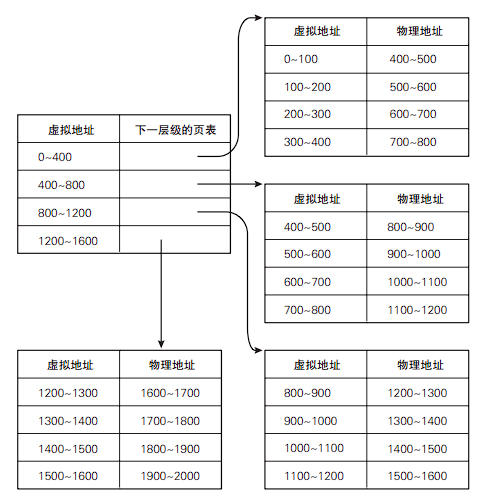
假设每页 100 字节,每级 400 字节的 2 级结构的页表为例,将页面置换成 400 字节的标准大页后,页表减少了一个层级。
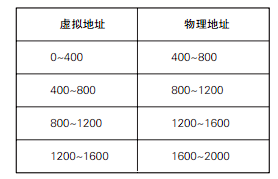
实际上的标准大页更加复杂,再 C 语言中,通过为 mmap 函数的 flags 参数赋予 MAP_HUGETLB 标准,可以获取标准大页。但在实际应用中,比起让编写的程序直接获取标准大页,更常用的方法是为现有程序开启允许使用标准大页的设置。
Linux 上还存在一个名为透明大页的机制。当虚拟地址空间内连续多个 4 KB 的页面符合特定条件时,通过透明大页机制能将它们自动转换成 一个大页。
多个页面 汇聚成一个大页的处理,以及当不再满足上述条件时将大页重新拆分为多 个 4 KB 的页面的处理等,会引起局部性能下降。为此,在搭建系统时, 有时会禁用透明大页。
存储层次
寄存器 > 高速缓存 > 内存 > 外部存储器,在这四个存储阶层中,其存储的容量逐渐增大,但其访问速度越来越低。
高速缓存
① 根据指令,将数据从内存读取到寄存器。
② 基于寄存器上的数据进行运算。
③ 把运算结果写入内存。
高速缓存的存在,为了抹平寄存器与内存之间的性能差距。 从高速缓存到寄存器的访问速度比从内存到寄存器的访问速度快了几倍甚至几十倍,利用这一点,即可提高流程①和流程③的处理速度。高速缓存通常内置于 CPU 内,但也存在位于 CPU 外的类型。
从内存往寄存器读取数据时,数据先被送往高速缓存,再被送往寄存器。所读取的数据的大小取决于缓存块大小(cache line size)的值,该值由各个 CPU 规定。
当需要将寄存器上的数据写到内存上时,首先把改写后的数据写入高速缓存,并为这些缓存块添加一个“脏了”标记,这些标记的数据会在写入高速缓存后的某个指定时间点通过后台处理写入内存。
这种模式称为回写(write back)。另外还存在一种名为直写(write through)的模式。 在直写模式下,缓存块会在变脏的一瞬间被立刻写入内存。
销毁缓存块是出现高速缓存不足时的情况,如果读写高速缓存中不存在的数据就要销毁一个现有的缓存块。
当需要销毁的缓存块脏了的时候,数据将在被销毁前被同步到内存中。 如果在高速缓存不足,且所有缓存块都脏了的时候向内存发起访问,那么将因高速缓存频繁执行读写处理而发生系统抖动,与此同时性能也会大幅降低
在最近的 x86_64 架构的 CPU 中,高速缓存都采用分层结构,称为多级缓存。各层级在容量、延迟以及“由哪些逻辑 CPU 共享”等方面各不相同。 构成分层结构的各高速缓存分别名为 L1、L2、L3(L 为 Level 的首字 母)。不同规格的 CPU 中的缓存层级数量也不同。在各高速缓存中,最靠近寄存器、容量最小且速度最快的是 L1 缓存。层级的数字越大,离寄存器越远,速度越慢,但容量越大。
文件系统
文件系统上存在两种数据类型,分别是数据与元数据。
● 数据:用户创建的文档、图片、视频和程序等数据内容。
● 元数据:文件的名称、文件在外部存储器中的位置和文件大小等辅 助信息
另外,元数据分为以下几种。
● 种类:用于判断文件是保存数据的普通文件,还是目录或其他类型 的文件的信息 。
● 时间信息:包括文件的创建时间、最后一次访问的时间,以及最后 一次修改的时间 。
● 权限信息:表明该文件允许哪些用户访问。
了文件的两种类型:保存用户数据的普通文件,以及 保存其他文件的目录。在 Linux 中还有一种文件,称为设备文件。
设备也存在很多种类,但 Linux 将以文件形式存在的设备分为两种类型,分别为字符设备与块设备。所有设备文件都保存在 /dev 目录下。 通过设备文件的元数据中保存的以下信息,我们可以识别各个设备。
● 文件的种类(字符设备或块设备)
● 设备的主设备号
● 设备的次设备号
总结
这本书比我想象的更适合新手去看,讲的比较基础并且用更简单的例子去讲复杂的概念,但是看了一遍过后还是发现了自己有很多遗忘、模糊的知识。好了!现在Linux 基础算是找回一些了。内核!启动!
参考
Linux – 将自己的shell脚本设置成命令_将shell脚本设置为命令_路遥万里的博客-CSDN博客
《Linux 是怎样工作的》